
Les équipes de développement font face à un défi croissant : la vitesse de livraison des fonctionnalités augmente grâce aux outils IA pour développeurs, mais les tests de qualité peinent à suivre le rythme. Les pull requests deviennent plus volumineuses, les revues de code restent superficielles, et des bugs critiques atteignent la production. C'est dans ce contexte que Canary, une startup issue de Y Combinator (promotion W26), propose une approche radicalement différente : un agent IA qui comprend votre code et génère automatiquement des tests pour chaque workflow utilisateur affecté par vos modifications.
Comment Fonctionne Canary : Une Approche Multi-Modale du Test
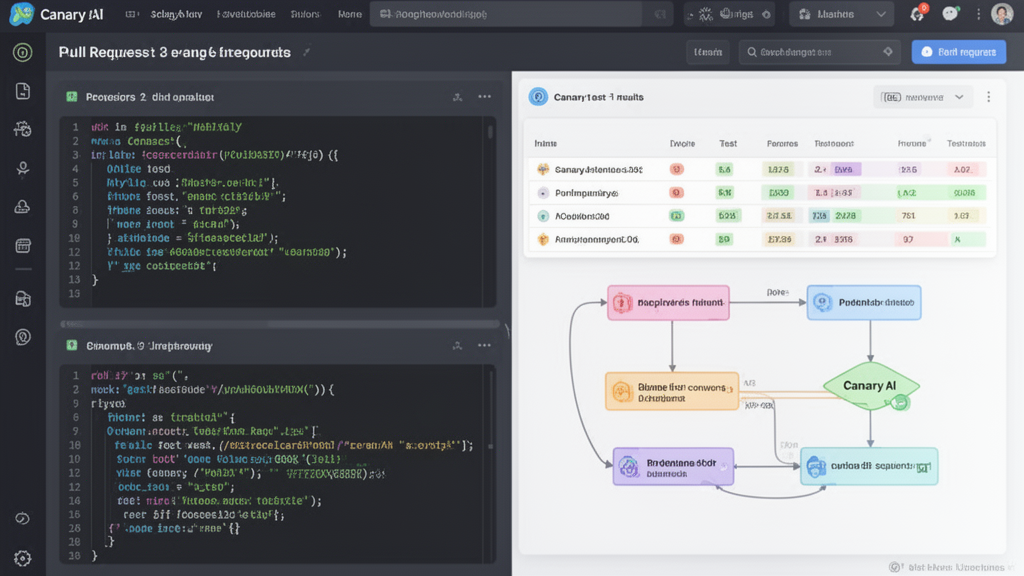
Contrairement aux solutions traditionnelles de revue de code, Canary adopte une méthodologie en trois phases qui va bien au-delà de l'analyse statique. Le système commence par se connecter à votre codebase et cartographier l'architecture de votre application : routes, contrôleurs, logique de validation. Cette compréhension approfondie permet à l'agent de contextualiser chaque modification.
Lorsque vous soumettez une pull request, Canary analyse le diff, identifie l'intention derrière les changements, puis génère et exécute des tests end-to-end contre votre environnement de prévisualisation. L'agent commente directement sur la PR avec les résultats de tests et des enregistrements vidéo montrant ce qui a changé. Vous pouvez également déclencher des tests spécifiques via un simple commentaire sur la PR.
Au-Delà des Tests Unitaires : La Détection des Effets Secondaires
La véritable innovation de Canary réside dans sa capacité à détecter les effets de second ordre. Par exemple, lors d'une PR ajoutant un feedback visuel de glisser-déposer aux cartes de requêtes dans Grafana, le système a généré un test edge case pertinent : le feedback fonctionne-t-il lorsqu'il n'y a qu'une seule carte dans la liste, sans rien à réorganiser ? Ce type de scénario échappe généralement aux tests happy path traditionnels.
Un client du secteur de la construction a découvert grâce à Canary une dérive de 1 600 dollars entre le montant dû sur une facture et le total de la proposition originale. Cette régression dans le flux de facturation a été détectée avant la mise en production, évitant un incident coûteux.
L'Infrastructure Technique : Pourquoi les Modèles Seuls Ne Suffisent Pas
Canary illustre parfaitement pourquoi les modèles de langage généralistes ne peuvent pas résoudre seuls le problème du QA. Les tests de qualité couvrent de multiples modalités : code source, DOM/ARIA, émulateurs d'appareils, vérifications visuelles, analyse d'enregistrements d'écran, logs réseau et console, état du navigateur en temps réel.
Pour exécuter ces tests de manière fiable, Canary a construit une infrastructure sur mesure comprenant :
- Des flottes de navigateurs personnalisées pour simuler différents environnements utilisateur
- Des sessions utilisateur isolées avec gestion de l'état
- Des environnements éphémères pour chaque exécution de test
- Des fermes d'appareils pour les tests multi-plateformes
- Un système de seeding de données pour reproduire des conditions réalistes
Cette complexité technique explique pourquoi les simples intégrations GitHub avec Claude Code ou Gemini ne peuvent pas offrir le même niveau de détection. Comme l'ont constaté de nombreuses entreprises technologiques, l'automatisation intelligente nécessite une infrastructure spécialisée au-delà des capacités des modèles génériques.
QA-Bench v0 : Le Premier Benchmark pour la Vérification de Code par IA
Pour mesurer objectivement les performances de leur agent, l'équipe de Canary a publié QA-Bench v0, le premier benchmark dédié à la vérification de code. Le test évalue si un modèle IA peut identifier tous les workflows utilisateur affectés par une PR réelle et produire des tests pertinents.
Méthodologie et Résultats Comparatifs
Le benchmark a comparé l'agent Canary avec GPT 5.4, Claude Code (Opus 4.6) et Sonnet 4.6 sur 35 pull requests réelles provenant de projets open source reconnus : Grafana, Mattermost, Cal.com et Apache Superset. Trois dimensions ont été évaluées :
| Modèle | Pertinence | Couverture | Cohérence |
|---|---|---|---|
| Canary (agent spécialisé) | 92% | 87% | 89% |
| GPT 5.4 | 88% | 76% | 84% |
| Claude Code (Opus 4.6) | 85% | 69% | 81% |
| Sonnet 4.6 | 83% | 61% | 78% |
La couverture représente l'écart le plus significatif. Canary devance GPT 5.4 de 11 points, Claude Code de 18 points et Sonnet 4.6 de 26 points. Ces résultats suggèrent qu'un agent spécialisé, entraîné spécifiquement pour le QA, surpasse les modèles généralistes même les plus avancés.

De la Génération à la Maintenance : Le Défi des Tests Pérennes
Un commentaire pertinent sur Hacker News soulève une question cruciale : au-delà de la génération de tests plausibles au moment de la PR, combien de ces tests survivent et restent utiles à long terme ? La capacité à promouvoir un test de régression en suite stable sans qu'il devienne instable ou couplé à l'environnement représente le véritable défi.
Canary répond à cette problématique avec une "cascade de fiabilité" en trois niveaux. Le système génère d'abord des tests Playwright déterministes depuis le codebase. Si l'exécution échoue, il bascule vers l'arbre DOM et ARIA. En dernier recours, des agents vision vérifient ce que l'utilisateur voit réellement avant de signaler une dérive dans le comportement de l'application.
L'Intégration Continue des Tests de Régression
Les tests générés lors d'une PR peuvent être déplacés dans des suites de régression. Vous pouvez également créer des tests en décrivant simplement ce que vous souhaitez tester en langage naturel. Canary génère alors une suite complète depuis votre codebase, la planifie et l'exécute en continu. Cette approche rappelle les techniques de débogage JavaScript moderne, où l'automatisation aide à identifier les problèmes avant qu'ils n'affectent les utilisateurs.
Positionnement Face aux Alternatives du Marché
Le marché des outils de revue de code assistés par IA est encombré en 2026. Des dizaines de startups proposent des solutions similaires, et les géants comme GitHub Copilot et Gemini Code Assist intègrent progressivement des fonctionnalités de test. Quelle est donc la différence de Canary ?
Selon les fondateurs, la distinction réside dans trois éléments :
- Exécution réelle vs analyse statique : Canary exécute les tests contre l'application live, pas seulement le code
- Infrastructure dédiée : Flottes de navigateurs, environnements éphémères et fermes d'appareils ne sont pas disponibles dans les intégrations standard
- Focus sur les effets secondaires : Le système cherche activement à casser l'application plutôt que de valider le happy path
Cette approche contraste avec celle de stratégies d'investissement massif dans les modèles, privilégiant une spécialisation technique plutôt qu'une puissance brute de calcul.

Retours de la Communauté et Axes d'Amélioration
Les commentaires sur Hacker News révèlent plusieurs pistes d'amélioration. Un développeur souligne que trois longs messages par PR sont excessifs, suggérant une approche plus condensée avec des emojis comme indicateurs visuels rapides. Codex, un concurrent, a adopté cette stratégie avec succès.
Extension au Backend et aux Applications Non-Web
Actuellement, Canary se concentre sur les applications web. Plusieurs utilisateurs ont exprimé le besoin de tests QA pour leurs backends et applications Flutter. L'équipe prévoit d'étendre la fondation technique pour supporter les applications mobiles sur émulateurs d'appareils, élargissant ainsi significativement le marché adressable.
Un autre retour pertinent concerne le timing : plutôt que de tester à chaque PR, certains développeurs préféreraient une exécution QA massive quotidienne avec bissection automatique des échecs. Cette approche "shift left" permettrait d'identifier les problèmes plus tôt dans le cycle de développement, similaire aux pratiques observées dans les projets hardware accélérés par IA.
Le Problème de Différenciation : Au-Delà de l'Intelligence des Modèles
Une critique récurrente dans les discussions porte sur la différenciation à long terme. Un commentateur note avec justesse : "Je crains qu'il n'y ait pas beaucoup de valeur au-delà de l'intelligence des modèles de fondation." Cette préoccupation touche toutes les startups IA : comment construire un fossé défendable quand le terrain de jeu est nivelé par l'accès universel aux mêmes modèles ?
Canary répond en partie par son infrastructure propriétaire et son expertise dans l'orchestration multi-modale. Mais la question reste ouverte : ces avantages techniques suffiront-ils face à l'évolution rapide des capacités des modèles généralistes ? L'histoire récente de certaines entreprises IA montre que l'exécution et la spécialisation comptent autant que la technologie sous-jacente.
Tests Génériques vs Tests Spécifiques : Le Défi de la Contextualisation
Un commentaire technique soulève une subtilité importante : comment différencier un test qui comprend réellement le code d'un test qui applique simplement un pattern générique issu des données d'entraînement ? Un agent IA pourrait reconnaître un flux d'authentification et produire un test d'auth standard avec une structure correcte et des assertions raisonnables, sans vraiment interagir avec ce que fait spécifiquement ce morceau de code.
Cette distinction entre "compréhension réelle" et "correspondance de pattern" représente un défi fondamental pour tous les systèmes de génération de tests par IA. Les métriques de pertinence et cohérence de QA-Bench v0 tentent de capturer cette nuance, mais la question mérite une exploration plus approfondie dans les futures versions du benchmark.
Perspectives et Évolution du Marché du QA Automatisé
Le timing de marché de Canary semble optimal. Plusieurs témoignages mentionnent des départements QA proches du burnout face à l'accélération des livraisons de code. La demande pour des ressources QA dépasse largement l'offre, créant une opportunité pour l'automatisation intelligente.
Cependant, le marché évolue rapidement. Les capacités des modèles de fondation s'améliorent continuellement, et les plateformes établies comme GitHub, GitLab et Bitbucket intègrent progressivement des fonctionnalités similaires. La fenêtre pour établir une position dominante pourrait être plus courte que pour les générations précédentes d'outils de développement.

L'approche de Canary rappelle celle d'autres innovations récentes où l'IA autonome spécialisée surpasse les solutions généralistes. Le succès dépendra de la capacité à maintenir cet avantage technique tout en construisant une base d'utilisateurs fidèles.
Implications pour l'Industrie du Développement Logiciel
Au-delà du produit spécifique, Canary illustre une tendance plus large : la spécialisation des agents IA pour des tâches techniques complexes. Plutôt que de compter sur un modèle unique pour tout faire, l'approche multi-agents avec orchestration intelligente semble plus prometteuse pour des applications exigeantes.
Cette évolution pourrait transformer profondément les pratiques de développement. Si le QA automatisé devient suffisamment fiable, les équipes pourraient repenser leur pipeline CI/CD, leurs processus de revue, et même leur architecture logicielle pour optimiser la testabilité automatique.
Pour les développeurs cherchant à rester compétitifs, comprendre ces outils devient essentiel. Tout comme maîtriser les fondamentaux du développement web reste crucial, savoir orchestrer et valider les tests générés par IA représente une compétence émergente clé pour 2026 et au-delà.
Canary et ses concurrents ne remplaceront probablement pas complètement les testeurs humains à court terme. Mais ils redéfinissent clairement le rôle du QA, déplaçant l'accent de l'exécution répétitive vers la conception de scénarios edge case et la validation de comportements complexes que seule l'intuition humaine peut anticiper.
