
En avril 2026, PrismML a dévoilé Ternary Bonsai, une famille de modèles de langage utilisant une représentation à 1,58 bits qui bouleverse les standards de l'industrie. Alors que les besoins énergétiques des data centers explosent, cette innovation technique propose une alternative radicale : des modèles 9 fois plus légers que leurs équivalents 16 bits, sans sacrifier leurs performances.
Cette avancée s'inscrit dans un contexte où l'efficacité énergétique et la portabilité des modèles d'IA deviennent des critères décisifs. Face aux controverses entourant certains acteurs du secteur, comme l'illustre l'affaire Mistral AI, l'approche de PrismML mise sur la transparence technique et l'open source.
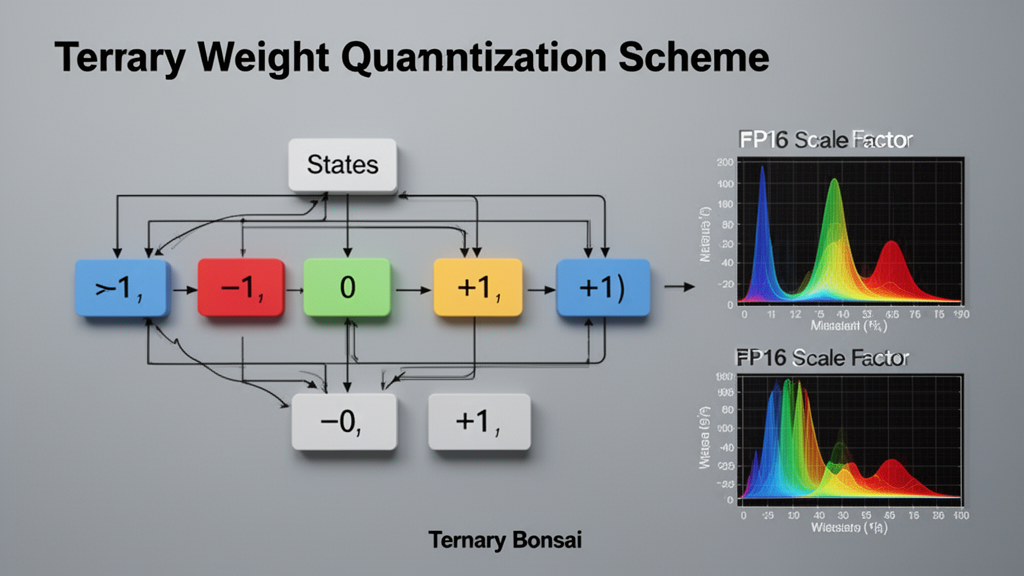
Qu'est-ce que la quantification ternaire à 1,58 bits ?
La quantification ternaire représente une rupture conceptuelle dans la conception des réseaux de neurones. Contrairement aux modèles traditionnels qui utilisent des poids en virgule flottante 16 bits (FP16), Ternary Bonsai contraint chaque poids du réseau à prendre l'une de trois valeurs seulement : {-1, 0, +1}.
Cette représentation utilise exactement 1,58 bits par poids, combinant l'encodage des trois états (-1, 0, +1) avec un facteur d'échelle FP16 partagé (s) pour chaque groupe de 128 poids. Le calcul est simple : chaque poids vaut soit -s, soit 0, soit +s, où s est un nombre en virgule flottante.
Une architecture entièrement ternaire
L'originalité de Ternary Bonsai réside dans son approche radicale : aucune échappatoire vers une précision supérieure. Les embeddings, les couches d'attention, les MLP et la tête de sortie utilisent tous la même représentation 1,58 bits. Cette cohérence architecturale garantit une efficacité mémoire constante à travers tout le réseau.
Cette approche contraste avec certaines techniques de quantification qui maintiennent des couches critiques en haute précision. Ici, PrismML démontre qu'une compression uniforme peut préserver les capacités de raisonnement du modèle.
Performances des modèles Ternary Bonsai
Les chiffres parlent d'eux-mêmes. Le modèle Ternary Bonsai 8B, avec seulement 1,75 GB de mémoire, atteint un score moyen de 75,5 sur les benchmarks standards, contre 70,5 pour son prédécesseur 1-bit Bonsai 8B (1,15 GB). Plus impressionnant encore, il surpasse la plupart des modèles 8B standard qui occupent 16 GB ou plus.
| Modèle | Taille | Score moyen | MMLU Redux | GSM8K | HumanEval+ |
|---|---|---|---|---|---|
| Qwen 3 8B | 16,38 GB | 79,3 | 83,0 | 93,0 | 82,3 |
| Ternary Bonsai 8B | 1,75 GB | 75,5 | 72,6 | 91,0 | 77,4 |
| RNJ 8B | 16,63 GB | 73,1 | 75,5 | 93,7 | 84,2 |
| Ministral3 8B | 16,04 GB | 71,0 | 68,9 | 87,9 | 72,6 |
| 1-bit Bonsai 8B | 1,15 GB | 70,5 | 65,7 | 88,0 | 73,8 |
| Llama 3.1 8B | 16,06 GB | 67,1 | 72,9 | 87,0 | 63,4 |
Densité d'intelligence : un nouveau paradigme
Le concept de densité d'intelligence (performance par gigaoctet) place Ternary Bonsai dans une catégorie à part. Avec un ratio performance/taille jusqu'à 9 fois supérieur aux modèles 16 bits, cette famille de modèles redéfinit ce qu'il est possible d'accomplir avec des ressources limitées.
Cette efficacité rappelle l'importance de l'optimisation des ressources dans tous les domaines technologiques, où faire plus avec moins devient un avantage compétitif décisif.
Débit et consommation énergétique : l'efficacité en pratique
Au-delà des benchmarks théoriques, Ternary Bonsai brille par ses performances réelles sur différentes plateformes matérielles. Les tests révèlent des gains substantiels en vitesse et en efficacité énergétique.
Performances sur matériel Apple
Sur un MacBook équipé de la puce M4 Pro, Ternary Bonsai 8B génère 82 tokens par seconde, soit environ 5 fois plus rapidement qu'un modèle 8B en 16 bits. Sur iPhone 17 Pro Max, le débit atteint 27 tokens par seconde, rendant possible l'exécution de modèles sophistiqués directement sur smartphone.
- M4 Pro : 82 toks/sec, 0,105 mWh/token
- iPhone 17 Pro Max : 27 toks/sec, 0,132 mWh/token
- Efficacité énergétique : 3 à 4 fois supérieure aux modèles 16 bits
- Latence réduite : réponses quasi-instantanées pour les applications mobiles
Cette efficacité énergétique prend une dimension particulière dans le contexte actuel, où les questions de souveraineté numérique incluent désormais la maîtrise de la consommation électrique.

Applications pratiques et cas d'usage
La légèreté de Ternary Bonsai ouvre des possibilités inédites pour l'intégration de l'IA dans des environnements contraints. Trois variantes (1,7B, 4B, 8B paramètres) permettent d'adapter le modèle aux besoins spécifiques de chaque application.
Déploiement sur appareils mobiles
L'exécution native sur iPhone et iPad transforme les smartphones en véritables assistants IA autonomes, sans dépendance au cloud. Cette capacité répond aux préoccupations croissantes concernant la confidentialité des données, particulièrement sensibles dans les secteurs éducatif et professionnel.
Intégration dans les workflows créatifs
Les créateurs de contenu peuvent désormais intégrer des capacités de génération de texte sophistiquées directement dans leurs outils, à l'image de l'évolution des outils graphiques. La faible empreinte mémoire permet d'exécuter Ternary Bonsai en parallèle d'autres applications gourmandes en ressources.
Opportunités commerciales
Pour les entrepreneurs explorant les opportunités économiques de l'IA, Ternary Bonsai réduit drastiquement les coûts d'infrastructure. Un serveur peut héberger plusieurs instances du modèle 8B là où un seul modèle 16 bits traditionnel saturait la mémoire disponible.
La frontière de Pareto : 1-bit versus 1,58 bits
PrismML ne positionne pas Ternary Bonsai comme un remplacement de sa famille 1-bit, mais comme une extension de la courbe de Pareto efficacité/performance. Chaque famille cible un point optimal différent selon les contraintes du projet.
Quand choisir 1-bit Bonsai
Les modèles 1-bit restent le choix privilégié lorsque l'empreinte mémoire absolue est la contrainte dominante : objets connectés, dispositifs embarqués, ou déploiements massifs où chaque mégaoctet compte. Avec 1,15 GB pour la version 8B, ils offrent la plus petite empreinte possible.
Quand privilégier Ternary Bonsai
Ternary Bonsai convient aux scénarios où 600 MB supplémentaires justifient un gain de 5 points de performance moyenne. Applications professionnelles, assistants conversationnels avancés, ou systèmes nécessitant une précision accrue bénéficieront de ce compromis.
Contexte technique et recherche sous-jacente
L'équipe de PrismML, issue de Caltech, s'appuie sur des années de recherche en compression de réseaux de neurones. Leur approche diffère des méthodes traditionnelles de quantification post-entraînement en intégrant la contrainte ternaire dès la conception du réseau.
Quantification consciente de la structure
La quantification par groupes de 128 poids n'est pas arbitraire. Cette granularité représente un équilibre entre la flexibilité du facteur d'échelle et la surcharge mémoire qu'il engendre. Chaque groupe partage un seul scalaire FP16, minimisant l'overhead tout en préservant la capacité du modèle à représenter des distributions de poids variées.
Entraînement natif versus quantification post-hoc
Contrairement aux techniques qui quantifient un modèle déjà entraîné, Ternary Bonsai est entraîné directement avec des poids ternaires. Cette approche permet au réseau d'apprendre à compenser les limitations de représentation, aboutissant à de meilleures performances finales qu'une simple conversion après coup.
Disponibilité et écosystème open source
PrismML distribue Ternary Bonsai sous licence Apache 2.0, favorisant l'adoption et l'innovation communautaire. Les poids sont disponibles sur Hugging Face, et l'intégration native avec MLX simplifie le déploiement sur l'écosystème Apple.
Outils et ressources disponibles
L'entreprise fournit un whitepaper détaillant l'architecture, les protocoles d'entraînement et les méthodologies de benchmark. Des démos interactives sur Hugging Face permettent de tester les modèles sans installation locale, similaires aux plateformes de test IA qui démocratisent l'accès aux technologies avancées.
Support matériel et compatibilité
Le support initial se concentre sur les appareils Apple (Mac, iPhone, iPad) via MLX, mais l'architecture ouverte facilite les portages vers d'autres plateformes. La communauté développe déjà des implémentations pour Android et des accélérateurs spécialisés.
Implications pour l'industrie de l'IA
Ternary Bonsai illustre une tendance de fond : l'optimisation architecturale devient aussi cruciale que l'augmentation brute de la taille des modèles. Cette philosophie contraste avec certaines visions de l'IA qui privilégient l'échelle à tout prix.
Démocratisation de l'IA avancée
En rendant des modèles performants accessibles sur du matériel grand public, PrismML contribue à démocratiser l'IA. Un développeur avec un MacBook ou un iPhone peut désormais expérimenter avec des capacités qui nécessitaient auparavant des clusters GPU coûteux.
Impact environnemental
La réduction de 75% de la consommation énergétique par token génère des économies substantielles à l'échelle. Si l'industrie adoptait massivement ces architectures compressées, l'impact environnemental global de l'IA pourrait diminuer significativement, répondant aux critiques concernant l'empreinte carbone du secteur.
Perspectives et évolutions futures
La sortie de Ternary Bonsai n'est qu'une étape dans l'exploration de l'espace des compromis efficacité/performance. PrismML suggère que d'autres points sur la courbe de Pareto méritent d'être explorés, potentiellement avec des représentations à 2 bits ou des architectures hybrides.
Vers des modèles multimodaux compressés
L'extension des techniques de quantification ternaire aux modèles vision-langage ou audio-texte représente une frontière naturelle. Les premiers travaux suggèrent que les gains d'efficacité se maintiennent dans les architectures multimodales, ouvrant la voie à des assistants IA complets sur appareils mobiles.
Spécialisation et fine-tuning
La communauté commence à explorer le fine-tuning de Ternary Bonsai pour des domaines spécifiques. Les premiers résultats indiquent que les modèles ternaires conservent une bonne capacité d'adaptation, similaire aux modèles spécialisés qui excellent dans leurs niches respectives.
L'approche de PrismML rappelle également l'importance des partenariats stratégiques dans le développement de l'IA, bien que leur choix de l'open source privilégie la collaboration ouverte plutôt que les alliances exclusives.


Conclusion : l'efficacité comme nouveau standard
Ternary Bonsai démontre qu'il est possible de repousser simultanément les frontières de la performance et de l'efficacité. En atteignant 75,5 de score moyen avec seulement 1,75 GB, le modèle 8B prouve que la compression extrême n'implique pas nécessairement de sacrifices majeurs en capacité.
Cette avancée arrive à un moment charnière, où les préoccupations concernant la régulation de l'IA et son impact sociétal s'intensifient. Des modèles plus légers, plus rapides et moins énergivores facilitent un déploiement responsable et durable de l'intelligence artificielle.
Pour les développeurs et entreprises cherchant à intégrer des capacités IA avancées dans leurs produits sans les contraintes d'infrastructure des modèles traditionnels, Ternary Bonsai représente une option convaincante. La disponibilité en trois tailles (1,7B, 4B, 8B) permet d'adapter précisément le modèle aux contraintes spécifiques de chaque projet.
L'initiative de PrismML s'inscrit dans un mouvement plus large vers une IA plus accessible et efficiente. Pour aller plus loin dans l'exploration des outils IA optimisés et découvrir comment intégrer ces technologies dans vos projets, créez votre compte gratuit sur Roboto et accédez à une plateforme complète de génération de contenu assistée par intelligence artificielle.


